이번에 피드줍줍 매니저라는 AI Agent를 개발했습니다. 간단하게 설명하자면, LLM을 통해 개발 DB에 데이터를 조회/삽입하거나, 팀 개발 문서를 검색해 주는 Agent입니다.
왜 만들었는가?
피드줍줍 팀 내 Discord 채널에 다음과 같은 알람이 왔습니다.

해당 팀원은 프론트 개발자인데요, 백엔드 개발자는 간편하게 DB에 접근해 insert 쿼리문 작성하면 되는 것이지만 프론트 팀원들은 애초에 DB 접속이 불가했기에 벌어진 상황이었습니다. DB에 데이터를 넣는 것 자체는 간단하지만 백엔드 팀원들이 부재중일 경우, 데이터를 넣어줄 때까지 기다림으로써 개발이 늦어지거나, 수동으로 400개 데이터를 넣어야 하는 상황이 발생할 수도 있죠.
최근 당근에서 출시한 AI 관련 서적을 읽고 AI를 활용해 팀원들의 생산성을 올린다던지, 자동화 시스템을 구축하는 것에 관심이 많던 시기여서, 직접 만들어보기로 했습니다.

(이 책은 한 번 읽어보시면 좋을 것 같아요 강추입니다!! 개발에 대한 시각을 바꾸게 된 것 같아요.)
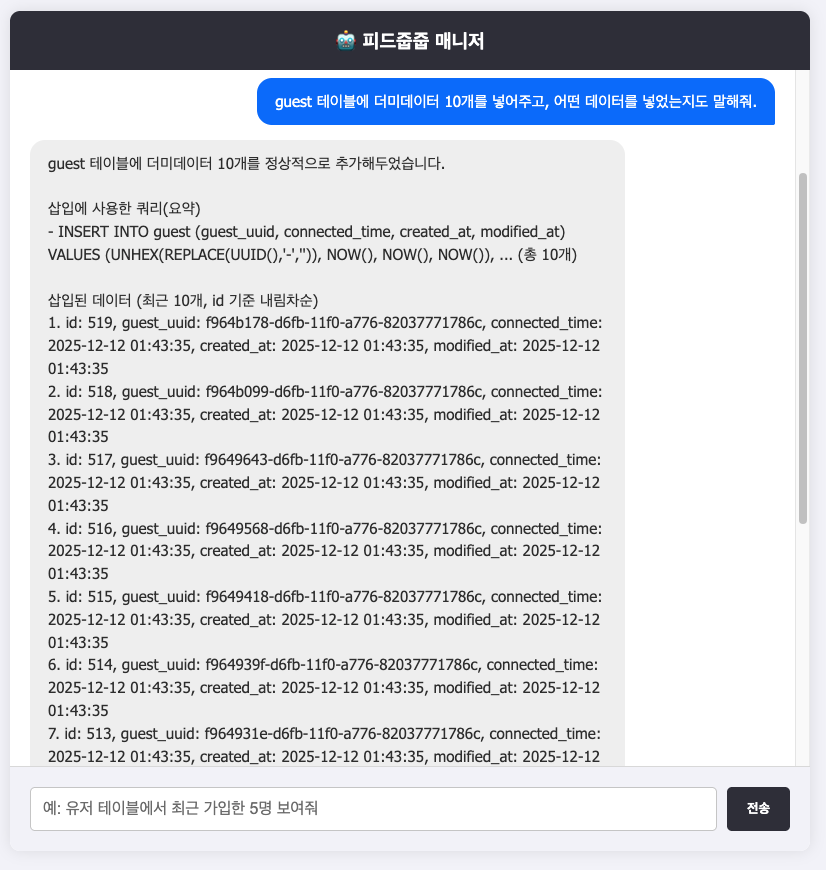
간단히 결과물에 대해 설명을 해보자면, 텍스트 메세지를 전송하면, LLM이 이를 쿼리로 변환해 직접 데이터를 삽입/조회하는 기능이 있습니다.
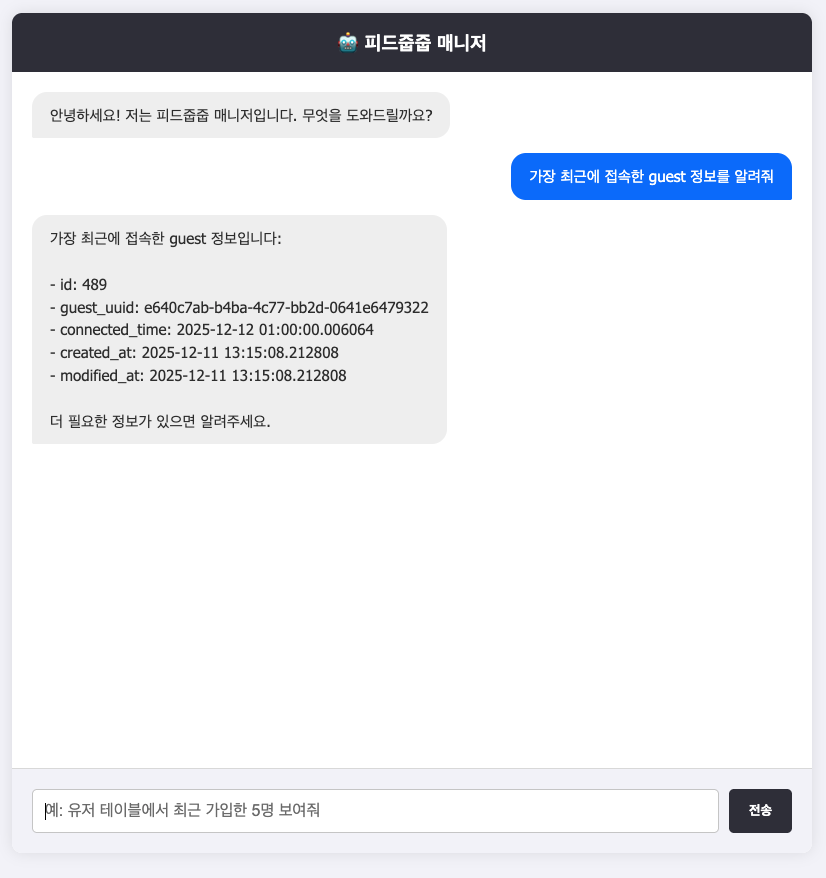
두 번째 기능으로는, 팀 내 API 문서에 대해 검색할 수 있습니다.


만약 존재하지 않는 API에 대해 물어볼 경우, 결과가 없다고 말을 합니다. LLM의 가장 큰 문제인 할루시네이션이 없는 것이죠. 어떻게 만들었을까요?
아키텍처 소개
아키텍처를 먼저 보면, 세부적인 동작을 이해하면 좋을 것 같습니다.

왜 이런 아키텍처를 선택했고, 어떻게 작동하는지 코드레벨까지 설명해보려고 합니다.
그 전에 이해해야 할 사전지식이 있는데요, 바로 Function Calling입니다.
Function Calling이란?
- LLM(대규모 언어 모델)이 사용자의 질문에 맞춰 미리 정의된 함수를 사용해 필요한 기능을 실행하도록 돕는 방식
간단한 예시를 들어 설명하자면,
'오늘 날씨는?'이라는 질문에 대해 AI는 답을 못 합니다. 하지만, '오늘 날씨는?'이라는 질문을 받을 때, 강남구의 날씨 정보 API를 호출하도록 미리 함수를 만들어놓으면, 해당 API의 응답값을 토대로 LLM이 답을 하는 것이죠.
하지만 Function Calling에는 몇 가지 단점이 존재합니다.
1) AI 모델마다 규격이 다르다
- OpenAI의 경우 tools 배열에 function 객체 형식을 사용해야 하고, Gemini의 경우 function_declarations 형식을 사용해야 하는 등 각 AI 모델마다 Function Calling을 정의하기 위한 Json 규격이 다릅니다.
2) stateless 하다.
- 각 요청은 이전 요청의 맥락을 기억하지 않습니다. 예를 들어서, 첫 번째로 user 테이블의 구조를 알려줘라는 질문을 하고, 두 번째로 거기에 age 컬럼을 추가해 줘.라는 컨텍스트가 불가능합니다. 이전 질문을 기억하고 있지 않기 때문이죠. 따라서 이 경우에는, 대화 히스토리를 직접 관리하거나, 첫 번째 + 두 번째 질문을 함께 호출해야 합니다. ex) user 테이블에 age 컬럼을 추가해 줘
그래서 위와 같은 문제점을 해결하기 위해 MCP 서버를 구축하기도 합니다.
그럼에도 불구하고 저는 MCP 서버를 구축하는 대신, Function Calling을 선택했습니다.
1) Spring AI는 Function Calling을 매우 간편하게 지원합니다. 함수를 빈으로 등록하기만 하면, Spring AI가 자동으로 이를 LLM이 호출할 수 있는 도구로 등록합니다. 이 과정에서, AI 모델을 바꿔도 Spring AI가 내부적으로 처리를 해주기에 규격을 안 바꿔도 됩니다.
2) 추후에 stateful 한 기능을 추가할 수도 있지만, 최대한 Spring AI를 활용해 빠르고 단순하게 아키텍처를 구현하고 싶었습니다.
위와 같은 이유로, 저는 MCP 서버를 구축하는 대신 Function Calling을 선택했습니다.
DB 조회/추가 구현
총 3개의 Function Calling을 만들어 빈으로 등록했습니다.
@Bean
@Description("Get the database schema DDL for all tables. Use this to understand table structures before writing SQL.")
public Function<Void, String> getSchema(final QueryService queryService) {
return request -> queryService.getAllTableDdl();
}
@Bean
@Description("Execute INSERT, UPDATE queries. NOT for SELECT.")
public Function<SqlRequest, String> executeWriteSql(final QueryService queryService) {
return request -> AiTaskWrapper.execute(() -> {
int rows = queryService.executeWriteQuery(request.sql());
return "Query executed successfully. Rows affected: " + rows;
});
}
@Bean
@Description("Execute SELECT queries to retrieve data from the database.")
public Function<SqlRequest, String> executeReadSql(final QueryService queryService) {
return request -> AiTaskWrapper.execute(() ->
queryService.executeReadQuery(request.sql())
);
}
각각의 함수들에 대한 설명은 네이밍이 명확하고 구현이 간단하기 때문에 넘어가도록 하겠습니다. 대신 알고 넘어가야 할 부분이 있는데요,
@Transactional
public int executeWriteQuery(final String sql) {
QueryValidator.validate(sql);
log.info("쓰기 쿼리 실행");
log.info("쿼리 : " + sql);
return jdbcTemplate.update(sql);
}
@Slf4j
public class AiTaskWrapper {
private AiTaskWrapper() {}
public static String execute(Supplier<String> action) {
try {
return action.get();
} catch (Exception e) {
log.warn("AI 도구 실행 중 예외 발생: {}", e.getMessage());
return "Error executing query: " + e.getMessage();
}
}
}
상단의 코드를 보고 일반적인 예외 처리와 다른 점을 발견하셨나요?
try-catch문으로 exception을 잡은 후 로그를 찍고 별도의 예외를 던지는 것이 아닌, Error 메시지를 반환하고 있습니다. 일반적인 HTTP 요청 처리에서는 예외가 발생하면, 예외를 상위로 던지고, ExceptionHandler에서 처리해 상태 코드를 반환하는데요, 왜 이런 구조로 코드를 작성했을까요?
AI Agent 동작 방식
일반적인 HTTP 요청의 흐름

이 경우 예외가 전파되고 바로 에러 코드를 반환하게 됩니다. 즉, LLM과의 연결이 끊기게 됩니다.
AI Agent의 흐름

응답값으로 텍스트 에러 메시지를 반환해 줍니다. 즉, 에러가 발생해도 String 메세지를 반환해주기에 별도로 에러 전파가 되지 않습니다. 이 경우에는 LLM과의 연결이 끊기지 않는것이죠. 이 때, LLM은 에러 메세지를 보고 왜 실패했지?? 에 대해 스스로 생각한 이후, 요청을 수정해 재요청을 할 수 있습니다. 이렇게 목표를 달성하기 위해 스스로 생각하고, 도구를 사용하며, 반복적으로 시도하는 시스템을 AI Agent라고 합니다.
간단한 예시 : 조직에 더미 데이터 하나 삽입하는 과정

그림을 통해, AI Agent가 어떻게 동작하는지 쉽게 이해하시면 좋겠네요.
(추가적으로, Spring AI에서는 내부적으로 try-catch문을 사용해 자동으로 에러를 텍스트로 변환하는 코드가 존재합니다. 확인을 못 한 부분인데, 조만간 리팩토링을 진행하려고 합니다.)
API 문서 검색
API 문서 검색은 Swagger 데이터셋을 사용했습니다.
검색을 하기 전에 데이터 저장 과정이 필요했는데요, 데이터 저장 과정은 다음과 같습니다.
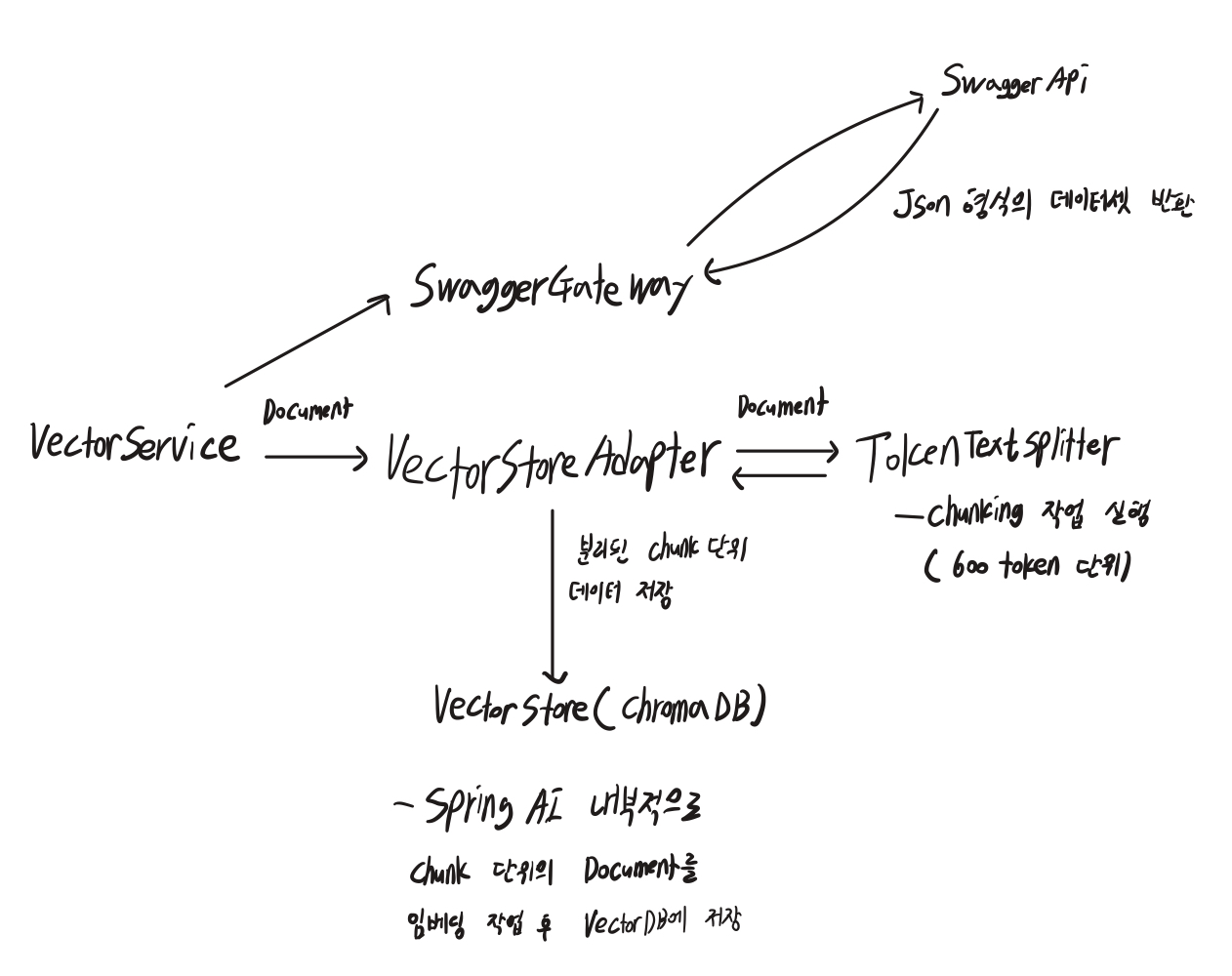
1) SwaggerGatway를 통해 Json 형식의 데이터 가져오기
2) VectorService에서 Document 생성 후, TokenTextSplitter를 통해 Document를 600 token 단위의 chunking 작업 실행
3) VectorStoreAdapter가 chunking 된 List <Document>를 vectorStore에 저장
4) vectorStore는 spring AI에서 제공해 주는 인터페이스임. SpringAI 내부적으로 청킹 된 Document를 임베딩 작업 후 연결해 놓은 VectorDB에 저장함
내부적인 코드는 해당 포스팅에서 별도로 다루지 않겠습니다. 혹 궁금하신 분이 있다면, 해당 Repository 참고 부탁드립니다.
https://github.com/CodingMasterLSW/feedzupzup-manager
GitHub - CodingMasterLSW/feedzupzup-manager: 피드줍줍 개발자들을 위한 편의 서비스
피드줍줍 개발자들을 위한 편의 서비스. Contribute to CodingMasterLSW/feedzupzup-manager development by creating an account on GitHub.
github.com
현재는 청킹을 기본값인 800 토큰 단위로 자르고 있습니다만, 이는 빠른 시일 내에 개선해야 할 부분입니다. 우선 빠르게 배포를 진행하고, 조금씩 성능을 개선하자라는 목표로 시작한 프로젝트였기에, 부족한 부분이 많습니다. 데이터를 API 별로 정제화하고, 청킹 단위를 조절해 보며 정확도를 비교해며 개선해나가려고 합니다.
저장 과정에 대한 설명은 마무리하고, 이제 검색 과정에 대해 설명해 보겠습니다.
Function Calling은 다음과 같은 함수를 사용하고 있습니다.
@Bean
@Description("Search technical documents (Swagger API, Team Rules) to answer questions.")
public Function<SearchRequestWrapper, String> searchKnowledgeBase(final VectorStoreAdapter vectorStoreAdapter) {
return requestWrapper -> AiTaskWrapper.execute(() ->
vectorStoreAdapter.searchSimilarDocuments(requestWrapper.query()));
}
searchSimilarDocuments가 핵심 함수인데요,
public String searchSimilarDocuments(final String query) {
List<Document> docs = vectorStore.similaritySearch(
SearchRequest.builder()
.query(query)
.topK(3)
.similarityThreshold(0.8)
.build()
);
if (docs.isEmpty()) {
return "관련된 데이터를 찾을 수 없습니다.";
}
return docs.stream()
.map(Document::getText)
.collect(Collectors.joining("\n\n---\n\n"));
}
유저의 입력을 분석하고, 해당 요청을 처리하기 위해 LLM이 검색 쿼리를 만듭니다. 그리고 해당 검색 쿼리에 대해 임베딩 작업을 진행하고, VectorDB에 있는 chunking 된 Document 단위와 비교하는 것이죠. 이렇게 검색된 관련 데이터를 LLM에 참고 정보로 제공하여, 더 정확한 답변을 생성하는 기술을 RAG(Retrieval-Augmented-Generation)라고 합니다.
유사도 측정을 0.8이라는 다소 높은 수치로 설정했습니다. 관련 API가 없으면 없다고 명확하게 말해주는 것을 의도했기 때문입니다. 해당 수치에 대해서는 계속해서 테스트를 해봐야 할 것 같습니다. (현재는 팀원들에게 빠르게 Agent를 제공하고 싶어서 테스트 없이 배포를 했습니다.)
topK(3)은, 가장 비슷한 유사도 3개의 Chunking 된 Document 3개를 가져오는 작업입니다. 800 Token은 약 3,200자인데요. API 단위별로 분리가 되어 있지 않아 잘리는 부분이 있겠다는 생각이 드네요. DB 삽입/조회는 어느 정도 완성이 된 것 같지만, RAG 기반 작업은 아직 부족한 부분이 많네요.
앞으로의 계획
피드줍줍 매니저를 만드는 데, 총 3일 정도 걸렸습니다. 핵심 기능만 빠르게 만들어 팀원들에게 제공했기에, 앞으로 개선해야 할 부분이 상당히 많습니다.
1) 더 많은 팀 문서를 관리해보려고 합니다. 팀 Notion의 데이터를 넣거나, Github Issue에 대한 데이터를 넣거나 등등... 현시점에서는 별 문제가 발생하지 않지만, 데이터의 양이 많아지거나 서로 다른 데이터들이 섞일 경우, 데이터 정제 과정도 고도화해야 할 것 같습니다(라벨링을 한다던지). 이 과정에서 많은 고민을 해야 할 것 같네요.
2) 토큰 소모량을 추적해보려고 합니다. 아무래도 개인 사비를 사용하고 있기 때문에, 토큰 사용량을 어떻게 하면 줄일 수 있을까?? 에 대해 생각해 볼 것 같아요.
3) Spring AI 문서를 찾아보니, 모델의 정확도를 탐색하는 테스트가 있는 것을 확인했습니다. 속도와 정확도는 반비례하는데요, 어떤 상황에서 피드줍줍 팀원들이 정확도를 챙기면서 빠르게 검색할 수 있는지 다양한 시도를 해보려고 합니다.
RAG라는 기술을 접하니, 정말 다양한 곳에 사용할 수 있겠다는 생각이 드네요. 시야가 넓어진 느낌입니다.
하고 싶은 게 참 많네요ㅎ... 한 단계씩 성장하는 피드줍줍 매니저를 기대해 주세요!