피드줍줍은 단일 서버에서 스케줄링을 통한 배치 작업을 진행하고 있었는데, 규모가 커지며 다중 서버로 확장이 되었습니다. 서버가 확장되면서 여러 가지 문제가 발생했는데, 그중 하나가 스케줄링 중복 발행 이슈입니다.
이를 해결하기 위해서는
1) 별도의 스케줄링 서버를 도입
2) 스케줄링을 직접 관리
두 가지의 선택지가 존재했는데, 서버비를 아끼기 위해 2번 방법을 선택했습니다.
Scheduler 기본 설정
스케줄링 관리할 겸, scheduler의 기본 설정부터 리팩토링을 진행해보았습니다.

By default, Spring uses a local single-threaded scheduler to run the tasks.
As a result, even if we have multiple @Scheduled methods, they each need to wait for the thread to complete executing a previous task.
https://www.baeldung.com/spring-scheduled-tasks
상단의 내용을 보면 알 수 있듯이, Spring의 @Scheduled는 기본적으로 단일 스레드(Single Thread)로 동작합니다. 이 방식은 단순하지만, 실행 시간이 긴 작업이 겹칠 경우 뒤따르는 작업들이 대기해야 하는 Blocking(지연) 이슈가 발생한다는 단점이 존재합니다.
저희 피드줍줍 서비스에서는 현재 다음과 같은 두 가지 핵심 배치 작업이 수행되고 있습니다.
- 게스트 접속 시간 업데이트
- 장기간 미접속 게스트 삭제
물론 현재는 각 작업의 실행 시간을 겹치지 않게 배분하여 운영할 수도 있습니다. 하지만 추후 자정(00:00)과 같이 특정 시간대에 실행되어야 하는 요구사항이 늘어날 경우, 단일 스레드 환경에서는 유연한 대처가 어렵다고 판단했습니다.
따라서 스레드 풀(Thread Pool)의 크기를 3으로 확장하는 설정을 적용했고, 작업들이 동시에 실행되더라도 병목 없이 안정적으로 스케줄링을 소화할 수 있는 환경을 구축했습니다.
@Configuration
@EnableScheduling
public class SpringSchedulerConfig {
@Bean
public ThreadPoolTaskScheduler taskScheduler() {
ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();
scheduler.setPoolSize(3);
scheduler.setThreadNamePrefix("scheduler-");
scheduler.setWaitForTasksToCompleteOnShutdown(true);
scheduler.setAwaitTerminationSeconds(60);
return scheduler;
}
}
해당 설정 중 gracefulShutdown을 설정하는 부분이 있는데요,
scheduler.setWaitForTasksToCompleteOnShutdown(true);
scheduler.setAwaitTerminationSeconds(60);
스케줄링 작업 도중, 서버가 종료되면 안 되기 때문에 스케줄링 작업이 끝날 때까지 최대 60초를 기다렸다가 서버를 종료시킨다는 설정입니다. 하지만 현재는 해당 설정을 진행해도 gracefulShutdown이 불가능한 상황인데요, Docker의 종료 설정을 따로 설정하지 않았기 때문입니다.
조금 더 자세히 설명해 보자면,
docker의 프로세스 종료 대기 시간 (default 10초) < spring graceful shutdown (60초)인 상황인데요, 10초가 지나면 docker가 강제로 process kill 명령어를 통해 spring을 종료시켜 버립니다. 이 상황에서는 graceful shutdown이 불가능한 것이죠. 이 부분은 추후에 포스팅해보겠습니다ㅎ_ㅎ
스케줄링 중복 발행 해결하기
위에서 말했다시피 현재 두 가지의 Scheduling 작업을 진행하고 있는데요, 각 상황에 대해서 어떤 문제가 발생했고, 어떻게 해결했는지에 대해 적어보려고 합니다.
1. Guest 상태 업데이트
문제에 앞서, 다중 서버에서 동시에 update query가 발생하면 어떻게 동작하는지에 대해 알면 좋을 것 같아 먼저 설명해 보겠습니다.
update 쿼리 발생 시, MySQL InnoDB 엔진에서는 해당 레코드에 X-Lock (배타적 락)을 겁니다. 여기서 말하는 X-Lock은, 락을 가지고 있지 않다면 해당 record에 대해 읽기/쓰기 전부 불가능하다는 것을 의미합니다.
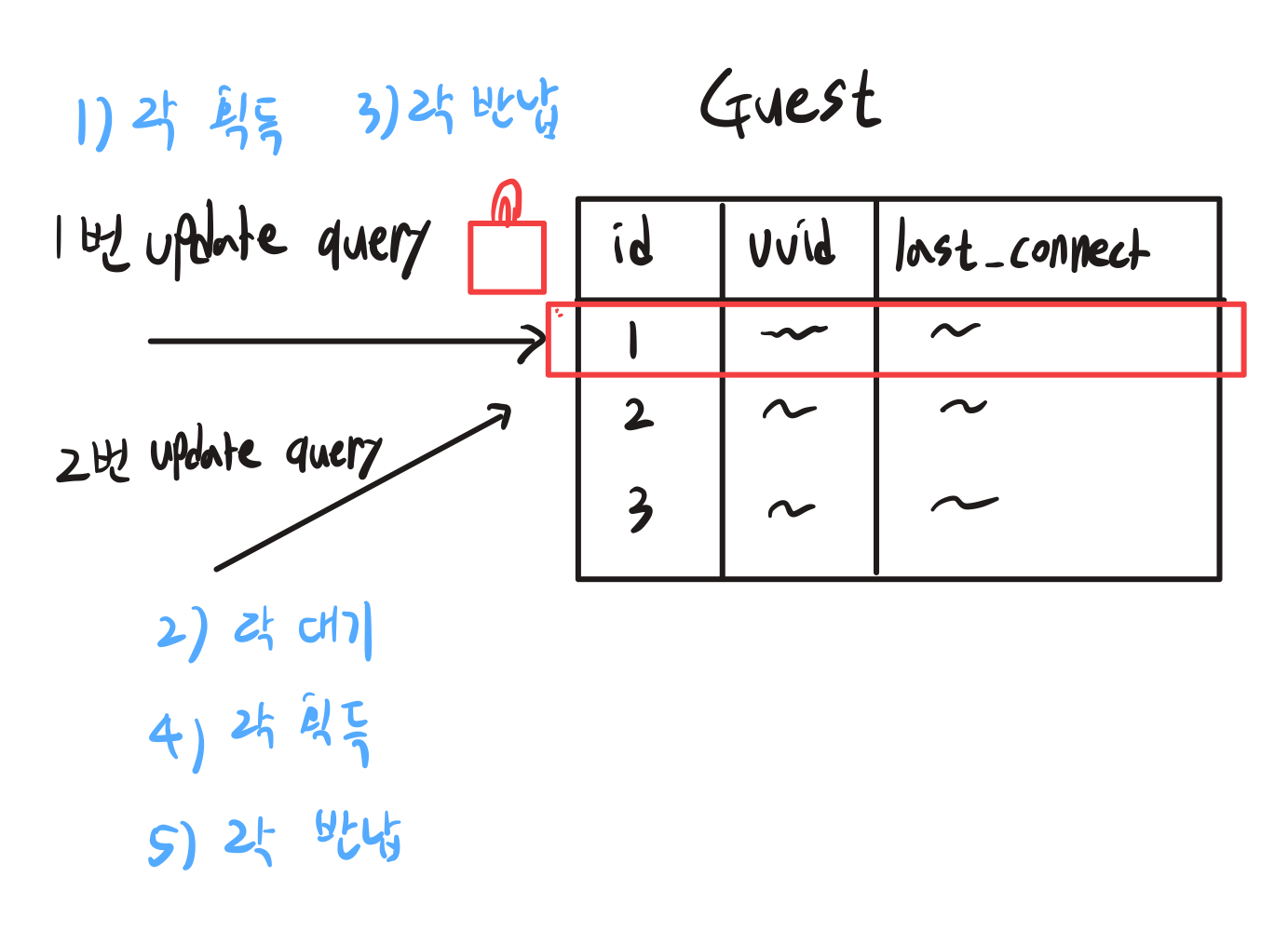
그림을 보면 알 수 있듯, 동시에 update 쿼리문이 발생했을 경우, 테이블의 record에 X-Lock이 걸리게 되고, 먼저 들어온 쿼리가 락을 획득합니다. 두 번째로 들어온 쿼리는 락이 없기에 대기하다가, 첫 번째 쿼리가 작업을 끝내고 락을 반납하면, 그제야 락을 획득하고 쿼리를 수행하는 것이죠.
다시 돌아와 Guest 상태 업데이트 배치 작업에 대해 설명해보려고 합니다.
해당 배치 작업은 하루동안 접속한 Guest 정보를 담고 있다가, 서버 메모리에 접속 기록이 존재한다면 last_connect 컬럼을 업데이트해주는 작업입니다. 해당 작업은 각 서버의 메모리에 있는 값들을 update 하는 것이고, 순차적으로 대기하다가 쿼리를 날리기에 중복 수행되어도 별 문제가 없을 것 같습니다.
하지만 해당 설계에서는 데드락 문제가 발생할 수 있는데요, 이에 대해 설명해보려고 합니다.
그전에 상황을 정확히 이해하려면 어떻게 guest를 추적하는지 알면 좋을 것 같은데요, 흐름은 다음과 같습니다.

피드줍줍 아키텍처에서는, ALB에서 Sticky Session이 아닌 Round Robin 방식으로 트래픽을 분산시키고 있는데요, 이 때문에 다른 서버의 메모리에 유저의 방문 기록이 중복 저장되어 있을 수 있습니다. user1이 server1로만 가는 게 아니라, 재접속을 하면 server2로 갈 수도 있는 것이죠.
즉 server A, server B 메모리에 유저의 방문 기록이 중복 저장이 될 수 있는 구조고, 이를 배치 처리 하면 deadLock이 발생할 확률이 상당히 높습니다.
Guest 테이블에 last_connection을 업데이트하는 쿼리가 동시에 발송되었다고 가정을 해보겠습니다.
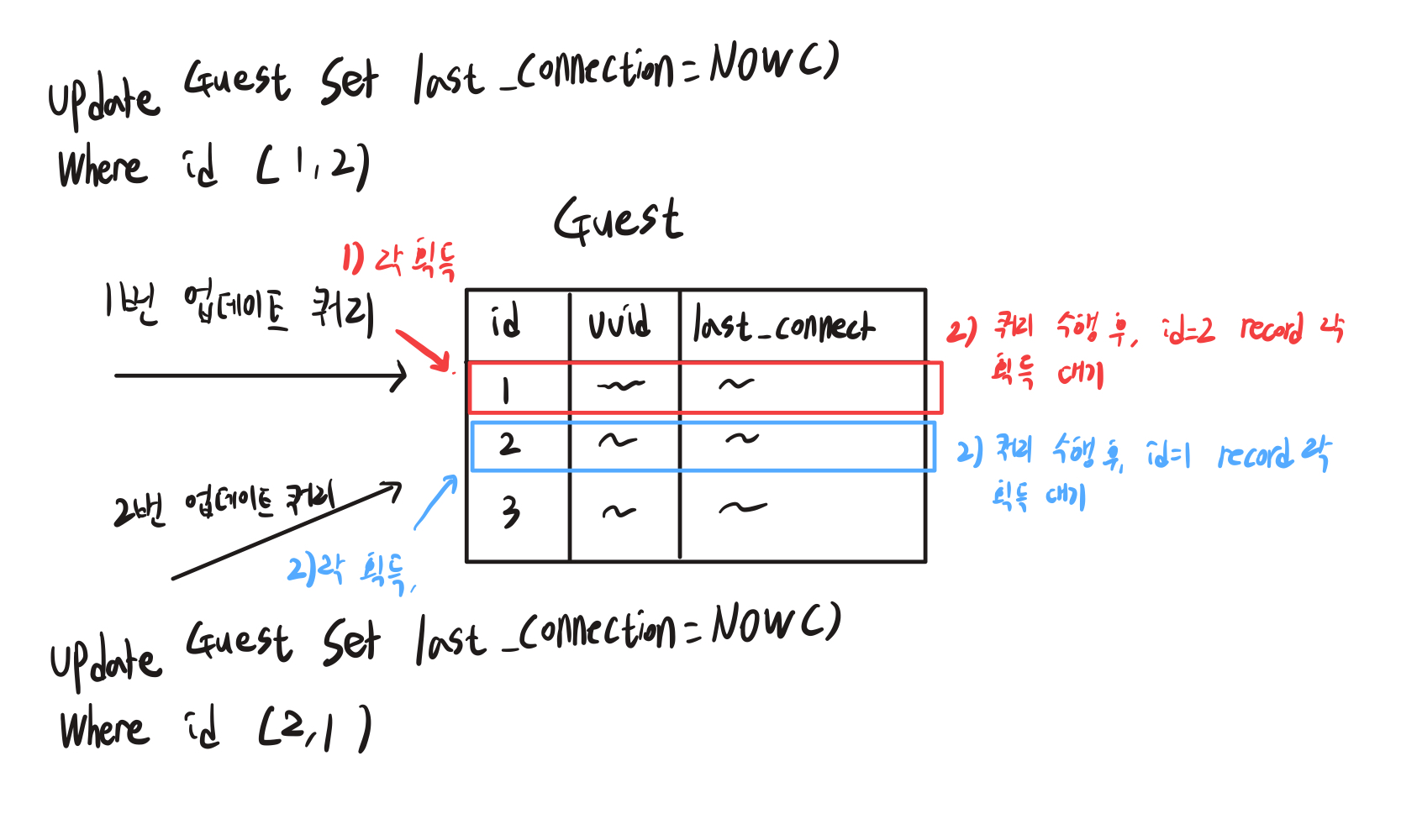
첫 번째 쿼리는 1,2번 Guest의 last_connect을 업데이트, 두 번째 쿼리는 2,1번 Guest의 last_connect를 업데이트합니다.
이 상황에서 데드락이 발생할 수 있는데요,
1번 쿼리가 id = 1인 record의 X-Lock을 획득하고, 쿼리 수행 후 id=2 X-Lock을 획득하기 위해 대기합니다.
2번 쿼리가 id = 2인 record의 X-Lock을 획득하고, 쿼리 수행 후 id=1 X-Lock을 획득하기 위해 대기합니다.
각 쿼리가 서로의 X-Lock을 획득하기 위해 대기하게 되고, 이를 DeadLock이라고 표현합니다. 본인들이 X-Lock을 들고 있기에 간단한 조회 쿼리도 대기를 하게 되고, 이는 심각한 장애로 발생하는 것이죠.
그렇다면 이 문제를 어떻게 해결할 수 있을까요?
저는 분산락을 통해 해당 문제를 해결했습니다.
1) Redis를 통한 분산락
2) MySQL의 getLock()
그중에서도 2가지 선택지가 존재했었는데요, 2번을 선택했습니다.
현재 아키텍처에서는 Redis가 없습니다. 이미 Redis를 사용하고 있어, Redis를 통해 분산락을 구현한다면 좋은 선택지겠지만, 분산락을 쓰자고 Redis를 사용하기에는 적합하지 않다고 생각했고, MySQL의 getLock()을 통한 NamedLock()을 사용하기로 결정했습니다.

그림으로 보면 더 확실하게 알 수 있는데요, Lock을 획득하기 전에는 update 쿼리를 실행하지 않기 때문에 deadlock이 발생하지 않습니다. 또, 이 경우에는 Guest 테이블 전체 Lock이 걸리는 게 아니기 때문에 다른 조회 쿼리의 성능에도 별다른 문제가 발생하지 않고요.
Guest 상태 업데이트 시 발생하는 데드락 문제를, 분산락을 통해 해결했다.라고 정리할 수 있을 것 같네요.
(구현 코드입니다)
@Component
@RequiredArgsConstructor
@Slf4j
public class GuestScheduler {
private final GuestService guestService;
@Scheduled(cron = "0 0 1 * * *")
public void updateDailyActiveGuestConnectedTime() {
log.info("Active 유저 업데이트 스케줄러 작동 시작");
int maxRetries = 3;
RetryExecutor.execute(
guestService::processUpdateWithLock,
maxRetries,
1000,
"Active 유저 업데이트"
);
log.info("Active 유저 업데이트 스케줄러 작동 완료");
}@Transactional
public boolean processUpdateWithLock() {
Integer result = lockRepository.getLock(GUEST_STATUS_UPDATE_KEY, 30);
if (result != null && result == 1) {
try {
final Set<UUID> activeGuests = guestActiveTracker.getTodayActiveGuests();
if (activeGuests.isEmpty()) {
log.info("금일 접속 사용자 수가 없습니다.");
return true;
}
final int updateGuestsCount = guestRepository.updateConnectedTimeForGuests(
activeGuests,
CurrentDateTime.create()
);
log.info("금일 접속 사용자 수 : " + updateGuestsCount);
guestActiveTracker.removeAll(activeGuests);
return true;
} finally {
lockRepository.releaseLock(GUEST_STATUS_UPDATE_KEY);
}
}
log.error("락 획득 실패 (timeout)");
return false;
}public interface LockRepository extends JpaRepository<Guest, Long> {
@Query(value = "SELECT GET_LOCK(:key, :timeoutSeconds)", nativeQuery = true)
Integer getLock(@Param("key") String key, @Param("timeoutSeconds") int timeoutSeconds);
@Query(value = "SELECT RELEASE_LOCK(:key)", nativeQuery = true)
Integer releaseLock(@Param("key") String key);
}
getLock()의 경우에는 MySQL에서 제공해 주는 함수입니다. Lock 테이블 또한 마찬가지고요. 사용자 입장에서는 간단하게 GET_LOCK만 해주면 끝이어서, 매우 간편합니다.
getLock() 함수에 대해 더 자세히 알고 싶다면, 하단의 문서를 추천합니다.
https://dev.mysql.com/doc/refman/5.7/en/locking-functions.html
https://techblog.woowahan.com/2631/
2) 일정시간 동안 접속하지 않은 Guest 삭제
이 경우에는, 무슨 문제가 발생할까요?
사실 Guest 삭제 쿼리는 중복 작동해도 별 문제가 없습니다. delete 쿼리는 원자성을 보장하기 때문이죠. 하지만, 굳이 불필요하게 쿼리를 한 번 더 보낼 필요가 있을까?라는 생각이 들어 추가적인 처리를 진행했습니다 (꼭 필요한 작업은 아니지만, 간단해서 진행해 봤습니다.)
이 경우에는 Guest 상태 업데이트와는 다르게 한 번의 배치 쿼리만 실행돼야 하는 것을 보장해야 하는데요, 이를 해결하기 위한 2가지 방법이 존재했습니다.
1) shedLock
2) getLock()
3) 별도의 스케줄링 서버 도입
결론부터 말하자면, 2번을 선택했습니다.
shedLock은 현 상황에서 적절하게 사용할 수 있는 라이브러리인데요, 굳이 불필요한 외부 라이브러리를 사용하고 싶지 않았고, getLock()을 사용해 통일성을 맞추고 싶었습니다.
shedLock 또한 좋은 선택지니, 관심이 있으시다면 한 번 살펴보면 좋을 것 같습니다.
https://github.com/lukas-krecan/ShedLock
GitHub - lukas-krecan/ShedLock: Distributed lock for your scheduled tasks
Distributed lock for your scheduled tasks. Contribute to lukas-krecan/ShedLock development by creating an account on GitHub.
github.com
getLock()을 통해 한 번의 배치 쿼리를 보장했는데요, 흐름은 다음과 같습니다.

Lock 획득을 하지 못하면, 아무 작업도 하지 않는 것이죠. 이렇게 설계를 하면, 한 번의 배치 쿼리만을 보장할 수 있습니다.
(구현 코드입니다)
@Transactional
public int removeUnActiveGuest() {
Integer result = lockRepository.getLock(GUEST_REMOVE_KEY, 0);
if (result != null && result == 1) {
try {
final LocalDateTime targetDateTime = CurrentDateTime.create().minusMonths(3);
final List<Long> unActivateGuests = guestRepository.findAllByConnectedTimeBefore(
targetDateTime);
if (unActivateGuests.isEmpty()) {
return 0;
}
writeHistoryRepository.deleteByGuestIdIn(unActivateGuests);
likeHistoryRepository.deleteByGuestIdIn(unActivateGuests);
guestRepository.deleteAllById(unActivateGuests);
return unActivateGuests.size();
} finally {
lockRepository.releaseLock(GUEST_REMOVE_KEY);
}
}
return 0;
}@Scheduled(cron = "0 5 1 * * *")
public void removeUnActiveGuest() {
log.info("비활성 유저 삭제 스케줄러 작동 시작");
final int deletedCount = guestService.removeUnActiveGuest();
if (deletedCount == 0) {
log.info("비활성 유저가 존재하지 않아 스케줄러 작동 패스");
return;
}
log.info("비활성 유저 {}명 삭제 완료", deletedCount);
log.info("비활성 유저 삭제 스케줄러 작동 완료");
}
(중요)
+ 2025.1.24 수정
해당 설계는 잘못된 설계라고 생각합니다. 너무 과한 오버엔지니어링이에요. 코드도 복잡해지고, 불필요한 성능 절감 포인트가 많네요.
데드락 발생 확률이 존재하는건 맞지만, Java 수준에서 정렬 후에 update 쿼리를 날리면 데드락 발생 확률이 극도로 낮다는 결론을 내렸습니다. 그럼에도 불구하고, MySQL의 옵티마이저가 정렬을 자기 멋대로 발생해 데드락이 걱정된다고 하면, 그냥 Scheduling 시에 약간의 시간차를 적용하면 될 것 같습니다.
추가로, MySQL의 NamedLock은 사용하기엔 간편해보이지만, 생각보다 고려해야 할 부분이 상당히 많은 것 같습니다.
1) 커넥션 자원 누수
getLock()을 하는 시점부터 release()를 할 때 까지 커넥션을 점유하는건 당연합니다. 하지만, Lock 획득을 대기하는 스레드 또한 커넥션 자원을 소모합니다. getLock()을 했을 때, MySQL 측에서 응답을 안 주고, 해당 커넥션을 대기 상태로 묶어버리는 구조입니다.
2) 별도의 커넥션 자원 분리
위와 같은 문제는 사실 심각한 문제입니다. 동시에 10개의 요청이 들어왔다면, 1개의 스레드는 작업을 수행함으로서 커넥션을 얻고, 9개의 스레드는 getLock() 대기를 하기 때문에 커넥션을 유지합니다.
즉, 최소한 NamedLock을 사용하기 위해서는 최소한 Application의 커넥션 풀과, Lock 획득을 위한 커넥션 풀을 분리해야 하지 않나 싶습니다. 복잡도가 점점 올라가는데, 이럴바에는 Redis 쓰는게 낫지 않나 싶네요ㅎ...
하나의 기능을 깊게 파려고 하니, 자연스럽게 공부해야 할 부분이 같이 나오는 것 같네요. 추후 포스팅에는 Graceful shutdown, Lock 종류에 대해 적어보려고 합니다.
혹, 궁금한 부분이 있거나 잘못된 부분이 있다면 댓글 남겨주시면 감사하겠습니다.
참고자료
https://www.baeldung.com/spring-scheduled-tasks
https://github.com/lukas-krecan/ShedLock
https://dev.mysql.com/doc/refman/5.7/en/locking-functions.html
https://techblog.woowahan.com/2631/
'프로젝트 > 피드줍줍' 카테고리의 다른 글
| 반복되는 집계 쿼리 개선하기 (0) | 2025.11.27 |
|---|---|
| 5xx 에러 로그 분석 자동화 (feat. n8n) (2) | 2025.10.30 |
| DB CPU가 터져요 (1편) (5) | 2025.09.29 |
| 우테코/피드줍줍 운영 기록기 (0) | 2025.09.15 |
| CodeRabbit 적용기 (3) | 2025.08.26 |



