사용자가 강의를 하며 실시간으로 Q&A 를 진행할 때 지속적으로 새로고침을 해야 하는 불편함이 있었습니다. 혹시 새로운 질문을 하는 사람이 있을까? 생각하며 계속 새로고침을 해야 하는 것이죠.
이 문제를 해결하기 위해 client 측에서 일정 시간마다 서버로 새로운 피드백이 있는지 요청을 보내고, 새로운 피드백이 생겼으면 토스트 메시지와 함께 새로고침 버튼을 표기해 줍니다.

해당 요청은 강한 실시간성이 필요하다고 판단하지 않아, 5초마다 client 측에서 요청을 보내고 있습니다. SSE 방식을 사용할 수도 있었지만 고려해야 할 부분이 많아, 우선 쉬운 polling 방식으로 빠르게 구현 후, 추후 마이그레이션 하는 방식을 선택했습니다.
이 부분에서 문제가 되는 점이 있었는데요, 바로 5초마다 집계쿼리가 반복적으로 수행된다는 점이었습니다. 집계쿼리는 CPU 집약적인 연산이라, 속도는 빠르지만 DB의 CPU 자원을 많이 소모합니다.
(문제의 집계쿼리)
@Query("""
SELECT new feedzupzup.backend.feedback.domain.FeedbackAmount(
COUNT(f),
COALESCE(SUM(CASE WHEN f.status = feedzupzup.backend.feedback.domain.ProcessStatus.CONFIRMED THEN 1L ELSE 0L END), 0L),
COALESCE(SUM(CASE WHEN f.status = feedzupzup.backend.feedback.domain.ProcessStatus.WAITING THEN 1L ELSE 0L END), 0L)
)
FROM Feedback f
WHERE f.organizationId = :organizationId
""")
FeedbackAmount countFeedbackByOrganizationIdAndProcessStatus(final Long organizationId);
client가 새로운 피드백이 왔는지 검증하기 위해 해당 집계쿼리를 사용하고 있습니다. 총 3개의 집계 쿼리를 사용하고 있는데요, 어느 수준까지 감당할 수 있을까요? 이를 확인하기 위해 부하테스트를 진행해 봤습니다.
Vus 100명, 1초에 1개씩 요청을 쏴봤을 때 결과입니다.
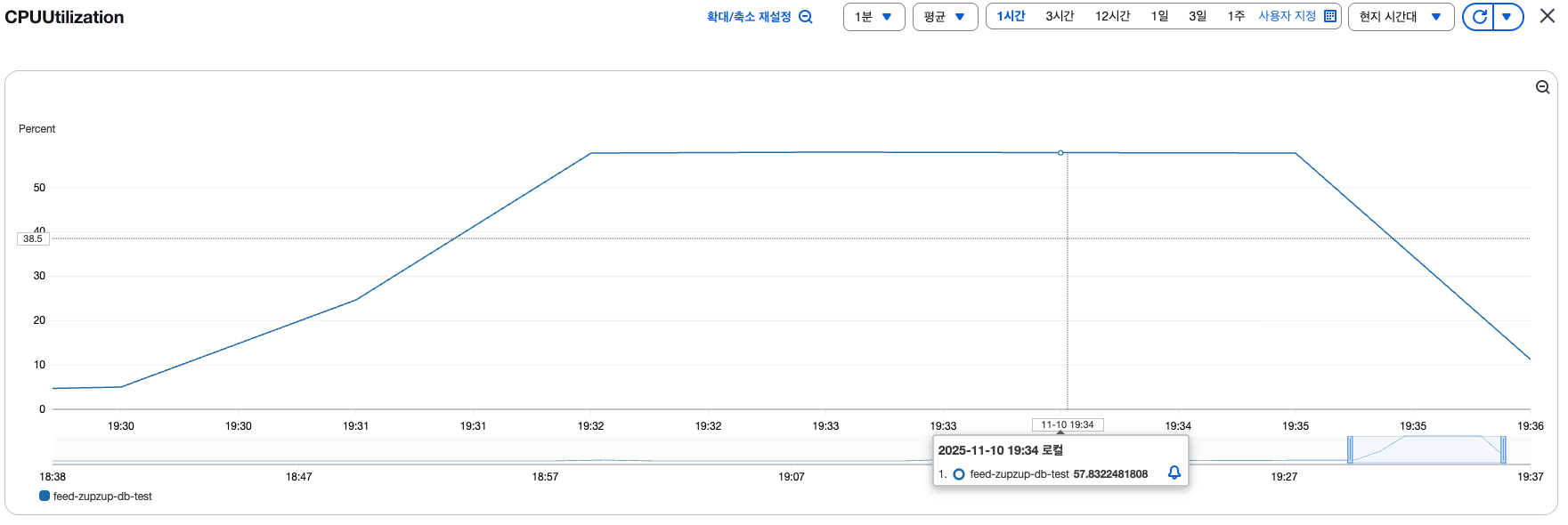


RDS CPU 사용량이 상당히 많이 올라가는데요, 이 구조에서는 100명이 접속했을 때 바로 문제가 생깁니다. 해당 API만 보내는 게 아니라, 5초에 500개씩 API 요청이 올 것이고, 500개 API + 다른 API 함께 요청이 오면 RDS CPU가 과부하가 발생하는 상황이죠.
이를 해결하기 위해 크게 두 가지 방법이 있었는데요,
1) 반정규화
2) 별도의 통계 테이블 도입
기존 Organization는 값이 잘 바뀌지 않은 데이터이기에 추후 캐싱 처리 하기에 용이하다고 생각했고, statistic 테이블의 추후 확장성을 고려해 2) 번을 선택했습니다.
별도의 통계 테이블을 도입하고 성능 테스트를 해본 결과, 수치가 어떻게 되었을까요?
부하테스트는 전과 동일하게, Vus 100 + 1초에 1번 요청을 보냈습니다.


결과는 정말 눈에 띄게 바뀌었는데요, CPU 사용률이 58% -> 9%로 개선되었고, p95 응답속도 또한 130ms -> 25ms로 감소했습니다.
어떻게 보면 당연한 결과이기도 한 것 같네요. 단순 API 조회만 하도록 변경되었으니깐요...!
별도의 테이블로 변경하기
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class OrganizationStatistic extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToOne(fetch = FetchType.LAZY)
private Organization organization;
@Embedded
private FeedbackAmount feedbackAmount;
public OrganizationStatistic(final @NonNull Organization organization) {
this.organization = organization;
this.feedbackAmount = new FeedbackAmount(0, 0, 0);
}
}@Embeddable
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class FeedbackAmount {
private long feedbackTotalCount;
private long feedbackConfirmedCount;
private long feedbackWaitingCount;
public FeedbackAmount(
final long feedbackTotalCount,
final long feedbackConfirmedCount,
final long feedbackWaitingCount
) {
this.feedbackTotalCount = feedbackTotalCount;
this.feedbackConfirmedCount = feedbackConfirmedCount;
this.feedbackWaitingCount = feedbackWaitingCount;
}
별도의 통계 엔티티를 만들었습니다. 쿼리는 단순히 OrganzationId를 통해 통계 테이블을 가져오는 쿼리입니다.
@Query("""
SELECT new feedzupzup.backend.organization.domain.FeedbackAmount(
s.feedbackAmount.feedbackTotalCount,
s.feedbackAmount.feedbackConfirmedCount,
s.feedbackAmount.feedbackWaitingCount)
FROM OrganizationStatistic s
WHERE s.organization.id = :organizationId
""")
FeedbackAmount findFeedbackAmountByOrganizationId(@Param("organizationId") Long organizationId);
이 과정에서 조회 성능을 더 향상하고 싶어 커버링 인덱스 도입을 고려해 봤었는데요, 해당 내용에 관심이 있다면 하단의 포스팅을 읽어보면 좋을 것 같습니다. (재밌는 내용이에요!)
https://codingmasterlsw.tistory.com/66
커버링 인덱스 vs 클러스터링 인덱스
이번에 성능 개선을 하려고 커버링 인덱스를 적용했었는데요, Optimizer가 커버링 인덱스 대신, 클러스터링 인덱스를 선택하더라고요...? 무조건 커버링 인덱스가 빠르지!라는 생각을 가지고 있었
codingmasterlsw.tistory.com
다시 본론으로 돌아오자면, 조회는 별 문제가 되지 않습니다. 중요한 건, 통계 테이블 값을 어떻게 업데이트하냐가 중요합니다.
통계 테이블의 스키마는 다음과 같습니다.

통계 테이블의 값을 업데이트해줘야 하는 경우는 크게 3가지 경우가 있습니다.
- 새로운 피드백이 작성되었을 때
- 기존 피드백이 삭제되었을 때
- 피드백의 상태가 변경되었을 때
즉, 위의 3가지 경우에 통계 테이블도 함께 업데이트를 해줘야 하는 것이죠.
@Transactional
@BusinessActionLog
public CreateFeedbackResponse create(
final CreateFeedbackRequest request,
final UUID organizationUuid,
final GuestInfo guestInfo
) {
final Guest guest = findGuestBy(guestInfo.guestUuid());
final Organization organization = findOrganizationBy(organizationUuid);
final Category category = Category.findCategoryBy(request.category());
final OrganizationCategory organizationCategory = organization.findOrganizationCategoryBy(
category);
final Feedback savedFeedback = feedbackRepository.save(request.toFeedback());
organizationStatisticRepository.updateOrganizationStatisticCounts(
savedFeedback.getOrganizationIdValue(),
CREATED_WAITING.getTotalAmount(),
CREATED_WAITING.getConfirmedAmount(),
CREATED_WAITING.getWaitingAmount()
);
return CreateFeedbackResponse.from(savedFeedback);
}
해당 코드는 현재 필요한 코드만 가져온 간략한 버전입니다. (이 외에 비동기로 추가 작업들을 진행하고 있습니다.)
피드백이 저장되는 동시에, 통계 테이블도 함께 업데이트를 진행해 줍니다. 관심사의 분리가 되지 않았네??라고 생각할 수도 있습니다. 저는 왜 단일 트랜잭션 구조를 선택했을까요?
데이터의 정합성
통계 테이블의 값은 정합성이 중요합니다. 새로운 피드백에 대한 검증을 통계 조회 API를 통해 관리하고 있기 때문이죠.
비동기 이벤트를 발행해 피드백 저장과 통계 업데이트의 결합도를 낮출 수 있지만, 이 과정에서 피드백은 저장되었는데 통계값이 저장이 안 되는 상황이 발생할 수도 있습니다. 새로운 피드백이 생겼지만, 새로고침 버튼이 안 보이는 것이죠.
명확한 트레이드오프 지점이라고 판단했고, 결합도를 가져가는 대신, 데이터 정합성을 가져가는 것으로 결정했습니다. 또, 통계 업데이트가 매우 가벼운 작업이라 기존 저장 과정에서도 큰 문제가 없을 것이라 판단하기도 했고요.
만약 통계 테이블이 새로운 피드백 검증에 사용이 되지 않고, 통계 관련 API에서만 사용되고 있었다면, 별도의 비동기 작업으로 분리했을 것 같네요. 또, 통계 업데이트의 비용이 큰 작업이었다면, 다시 고려해 볼 것 같긴 합니다. 이와 관련해 기존 피드백 삭제와 피드백 상태 변경 시에 비동기 작업을 고려하기도 했으나, 통일성을 지키는 게 관리하기 쉬울 것 같아 단일 트랜잭션으로 결정했습니다.
개발을 하다보면 다양한 트레이드 오프 지점을 만나는 것 같습니다. 정해진 답이 없는게 참 재밌네요ㅋ.ㅋ
'프로젝트 > 피드줍줍' 카테고리의 다른 글
| 다중 서버에서의 스케줄링 (feat. Lock) (0) | 2025.11.20 |
|---|---|
| 5xx 에러 로그 분석 자동화 (feat. n8n) (2) | 2025.10.30 |
| DB CPU가 터져요 (1편) (5) | 2025.09.29 |
| 우테코/피드줍줍 운영 기록기 (0) | 2025.09.15 |
| CodeRabbit 적용기 (3) | 2025.08.26 |



