SSE 연결에 대해 심화 학습을 해보고자 해당 포스팅을 작성하게 되었습니다.
사용자가 점점 늘어나는 상황에서 SSE 연결을 관리해야 할 때, 어느 부분에서 문제가 발생하는지를 알고 싶었습니다.
사전 설명
- t4g.large 단일 인스턴스로 시작
- t4g.large의 경우에는 8GB 메모리를 사용함
- JVM Heap 메모리를 따로 설정한 적이 없기에, 기본적으로 2GB 메모리가 할당되는것을 확인
동시 접속자가 많아지면 두 파트에서 문제가 생길거라고 생각했습니다.
1. 연결 2. 이벤트 발송
한 번에 다루기에는 너무 방대하기에, 해당 포스팅에서는 SSE 연결 측면에 관한 문제점만 다루도록 하겠습니다.
SSE 연결 관점에서의 문제점
시작 - 5,000명
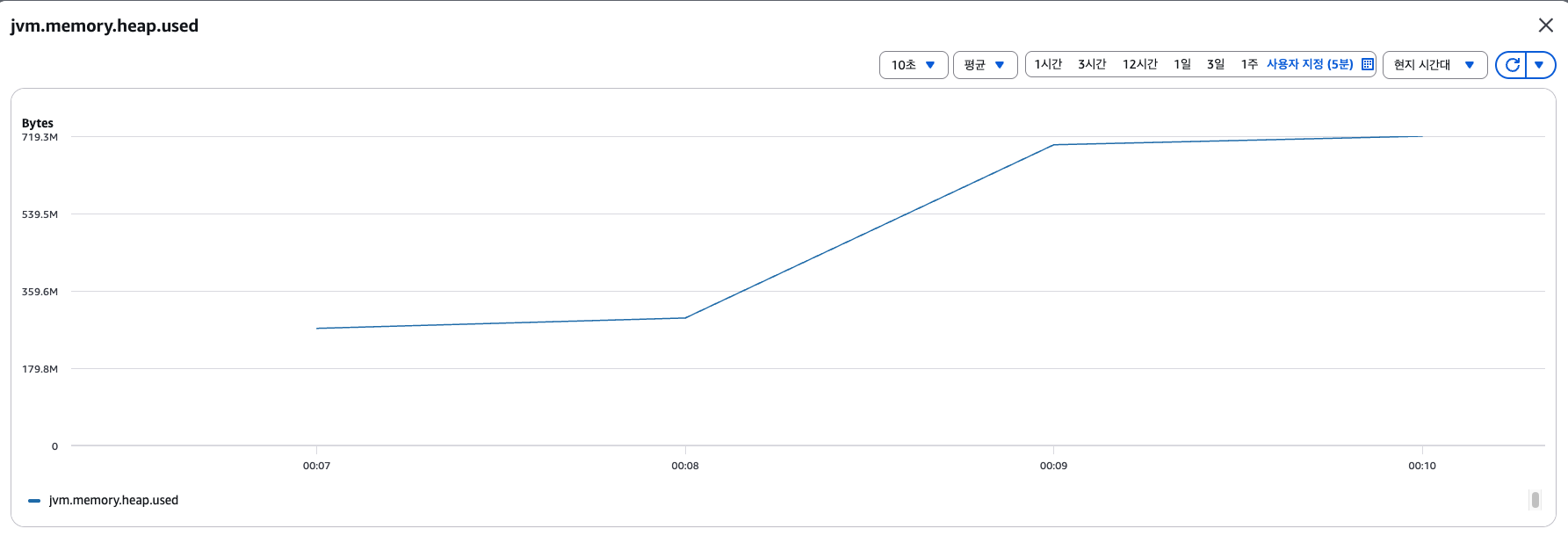
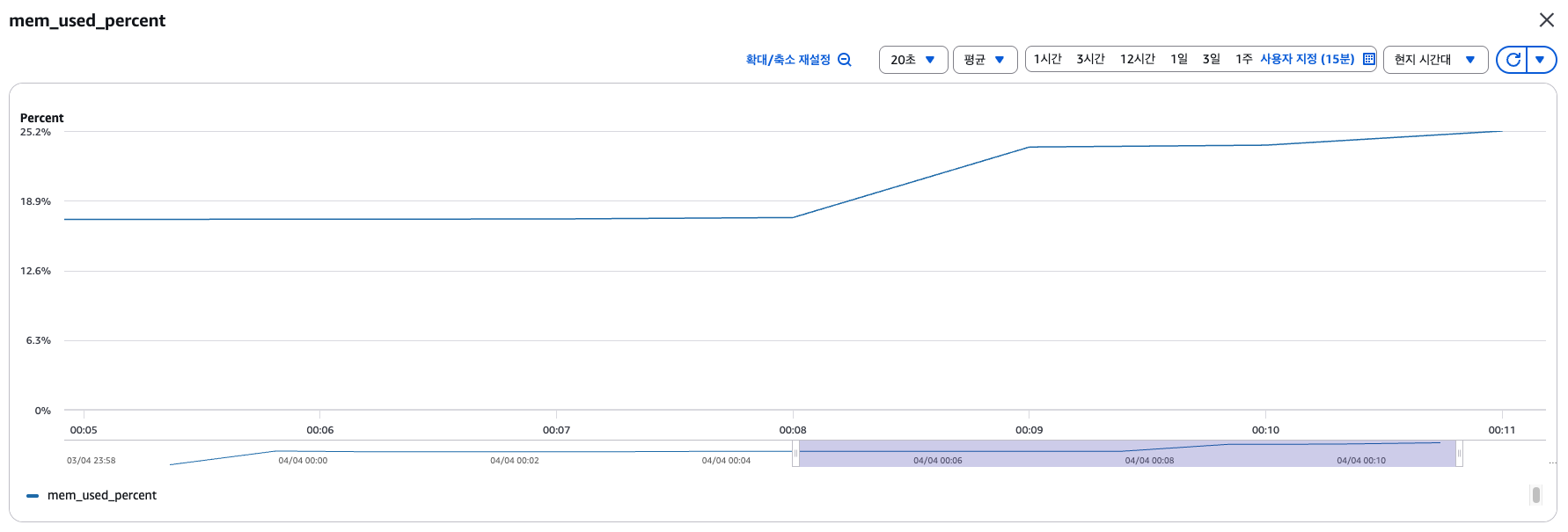
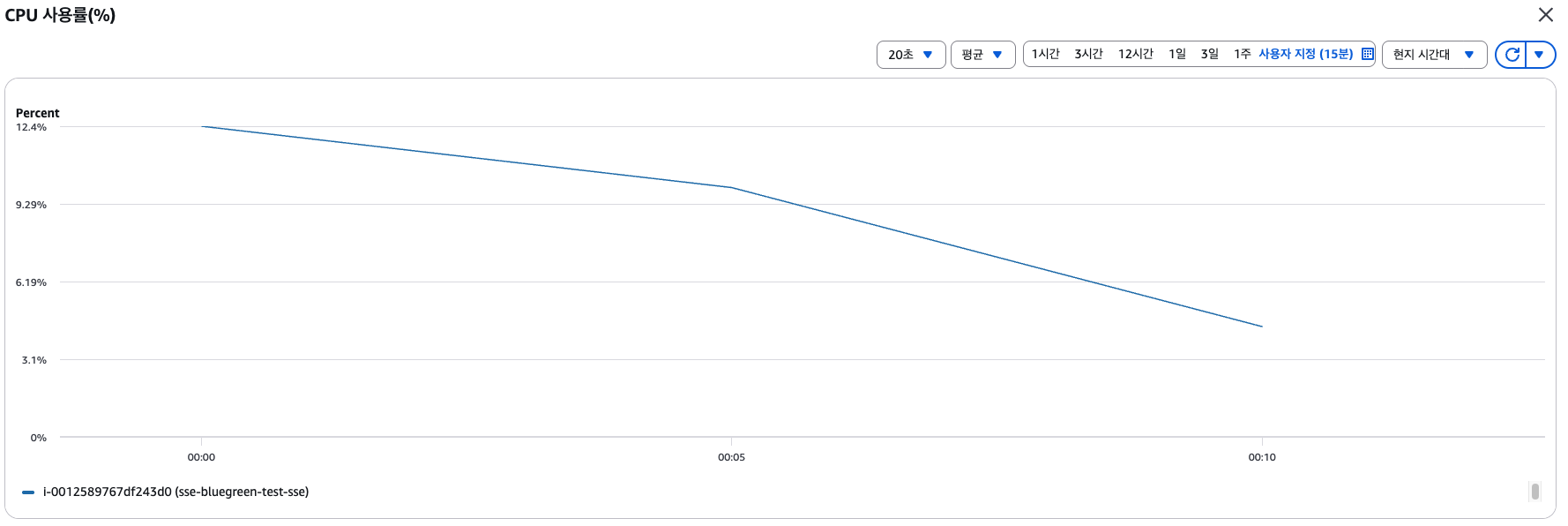

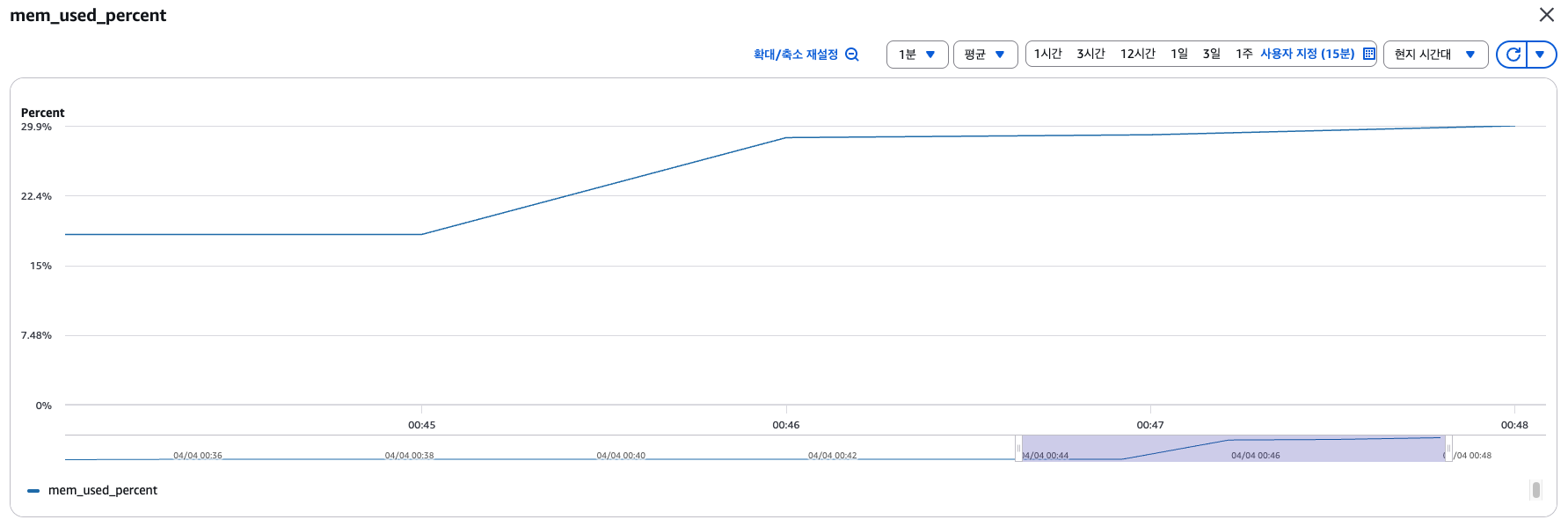
지표 분석 결과
- Heap 메모리 사용률이 270M -> 720M으로 상승 (약 450M)
- 전체 메모리 사용률 또한 17% -> 25%로 상승 (약 8%)
- CPU 사용률은 무관함 (오히려 줄어들음)
지표 분석 결과, Heap Memory 사용 할당량이 2GB니까 5,000개의 사용은 널널하다는 것을 알 수 있었습니다.
결론: 5,000개의 연결에서는 실패하는 연결이 하나도 발생하지 않았음.
중요) 반드시 File Descriptor의 설정값을 확인해야 합니다.
File Descriptor 설정을 하지 않고 Linux를 통해 서버를 띄우거나, 도커로 띄우지만 Docker Engine V29 이상을 사용하시는 분들이라면 에러가 발생합니다.
File Descriptor의 기본 최댓값은 1,024입니다.
연결 5,000개 = 소켓 5,000개 = FD 5,000개
즉 5,000개의 연결을 맺으려고 하면 Too many open files 에러가 발생합니다. 저의 경우에는 사전에 File Descriptor값을 넉넉히 설정해 오류가 발생하지 않았습니다.
(Docker의 File Descriptor 설정과 관련해 추가로 궁금한 점이 있으시다면, 해당 포스팅을 추천드립니다.)
https://codingmasterlsw.tistory.com/82
SSE Too many open files (feat. Docker)
Too many Open Files 발견...!! 이유가 뭘까?? Too many open files 에러가 발생했다는건, File Descriptor의 최댓값을 초과한 상황입니다. File Descriptor 설정을 따로 건드린 적은 없는데... 왜 갑자기 에러가 발생했
codingmasterlsw.tistory.com
10,000명
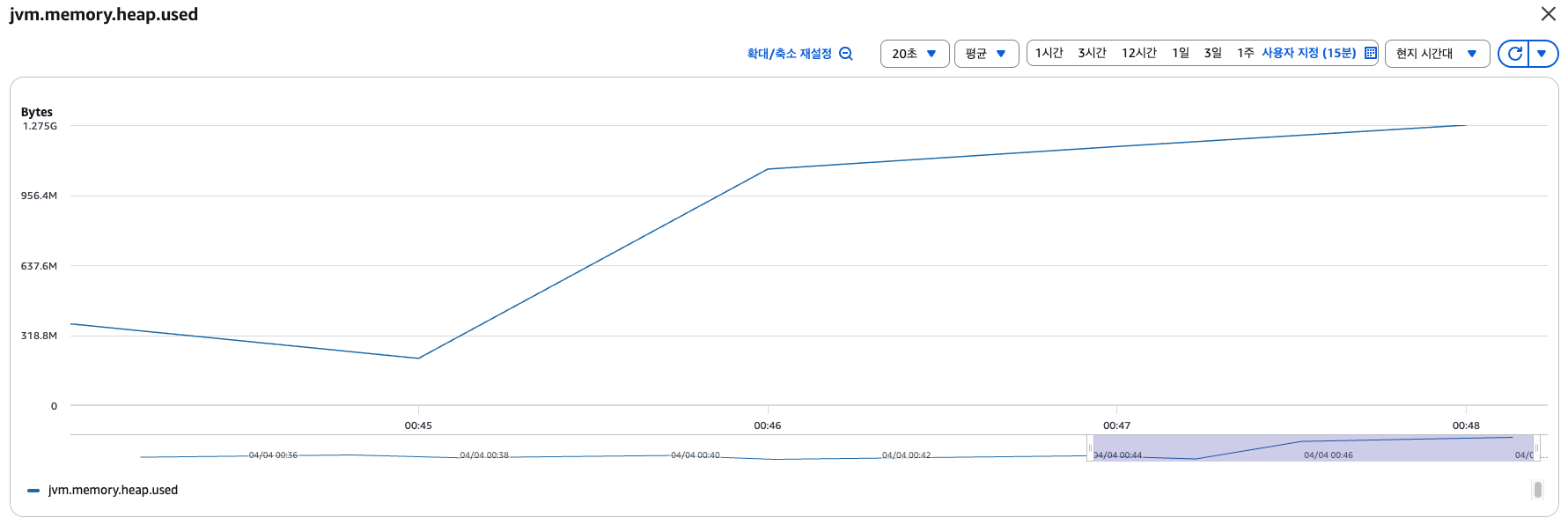

Server 측 로그

Client 측 응답

지표 분석 결과
- Heap 메모리 사용률이 300M ->1275M으로 상승 (약 975M)
- 전체 메모리 사용률 또한 17% -> 30%로 상승 (약 13%)
- 메모리는 여유가 있는 상황이지만, SSE Connection은 8192개에서 더이상 올라가지 않음. 나머지 1808의 요청이 SSE 연결에 실패하는 상황 발생
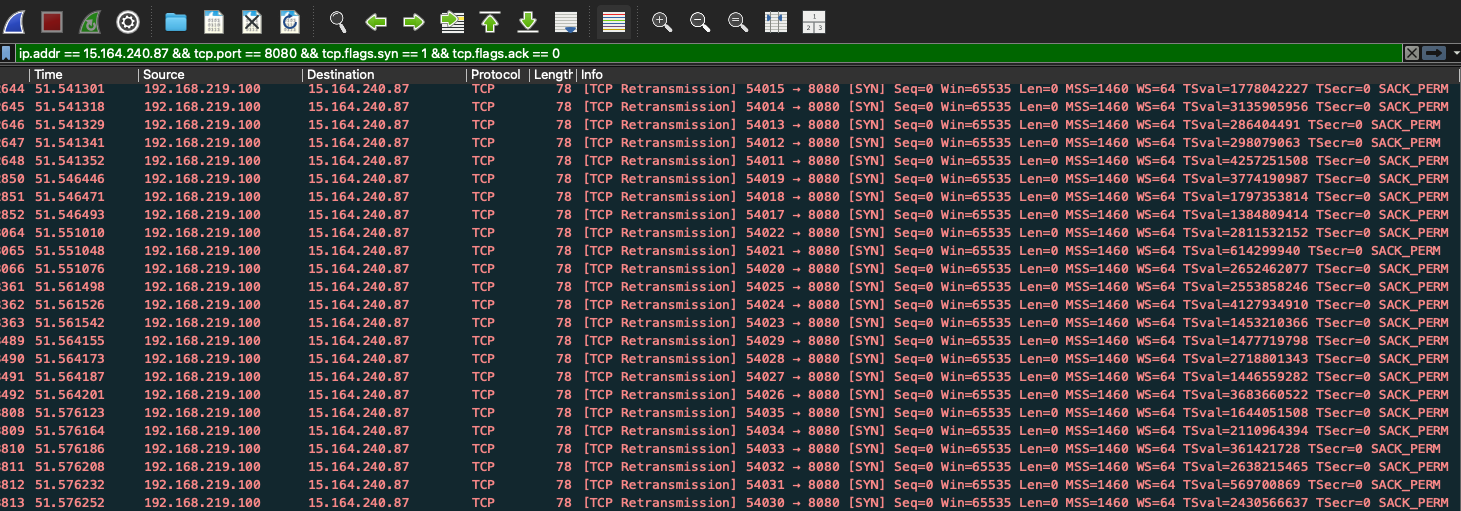
패킷을 분석해보니 2가지 문제 상황이 발생한 것을 알 수 있었습니다.
1) TCP 연결 자체가 안 되었음
Client 측에서 SYN을 보냈지만, SYN- ACK를 못 받은 경우입니다. TCP Handshake 자체가 거부되었다는 것을 알 수 있었죠.

Tomcat NIO Connector의 경우 다음과 같은 기본값을 가지고 있습니다.
- maxConnections : 8192
- acceptQueue : 100
TCP 연결 자체가 수립이 안 된 경우는 Tomcat의 기본 설정값인 maxConnections + acceptQueue가 가득차서 발생한 상황이었습니다. 이 경우에는 Tomcat 측에서 아무런 응답을 주지 않아 Client측에서 TCP 재연결 요청을 보내는 것이죠.
2) TCP 연결 자체는 성공했지만, Application 측에서 응답을 주지 않는 상황
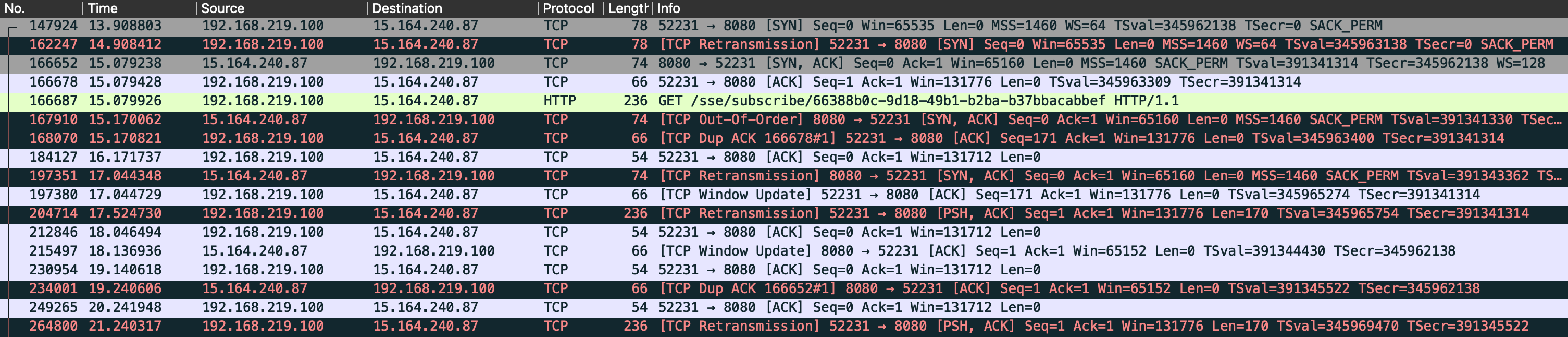
이 경우에는 TCP 연결 자체는 생성되었지만, maxConnections이 가득 차 acceptQueue에서 대기하고 있는 상황입니다. TCP 연결을 맺은 후에 acceptQueue에서 대기하기 때문에 TCP 연결 자체는 생겼지만, Connections이 비워지지 않아 Acceptor가 꺼내가지 않아 대기를 하는 상황이죠.
1)과 2) 모두 클라이언트 입장에서는 장시간 응답 없이 대기하다가 타임아웃됩니다. 서버가 명시적인 에러를 돌려주지 않기 때문에, 클라이언트는 서버가 느린 건지, 죽은 건지, 네트워크 문제인지 구분할 수 없죠. 이 경우, 클라이언트를 무한정 대기시키는 방법 대신 빠르게 503 에러를 보내주는 것도 하나의 대안일 것 같네요.
제가 생각한 해결방안은 다음과 같습니다.
- maxConnections를 메모리 여유에 맞게 늘리기
- SSE 연결 수가 임계치에 도달하면 즉시 503 응답
- 모니터링 환경 구축
- 실시간 Connection을 추적하면서 임계치 도달 시 ASG를 통한 scale-out을 하기
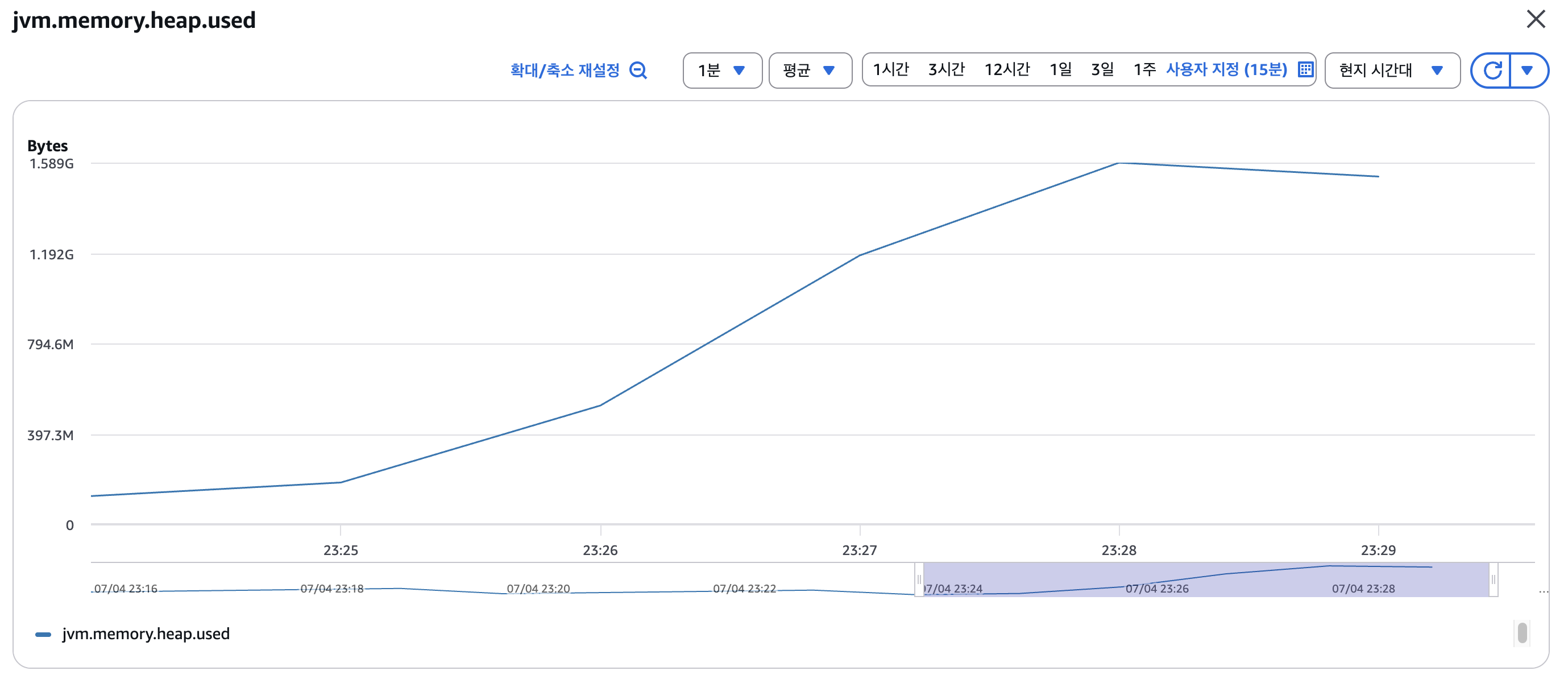
maxConnections를 15,000개로 조정 후 다시 테스트 해본 결과 10,000개의 연결을 잘 관리하는 것을 확인할 수 있었습니다.

100,000명
OOM 발생
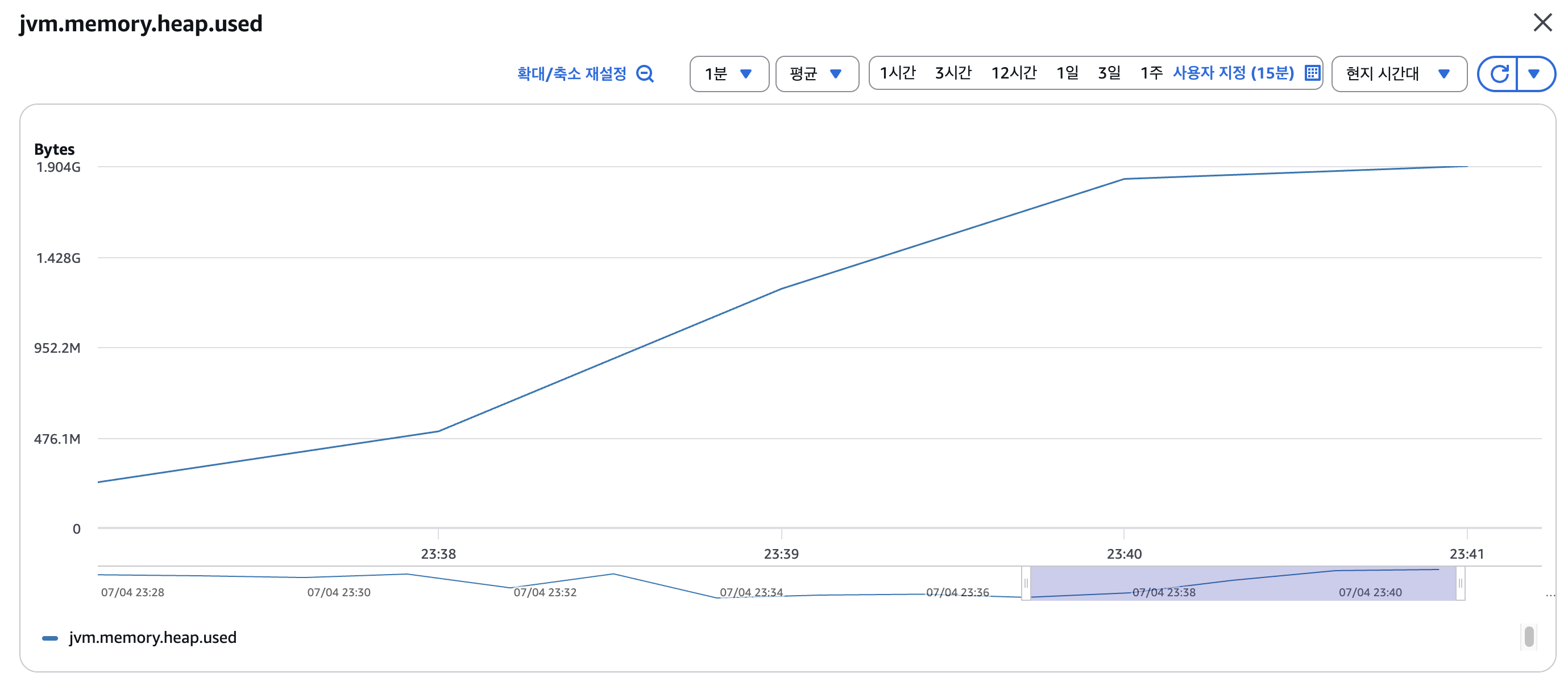
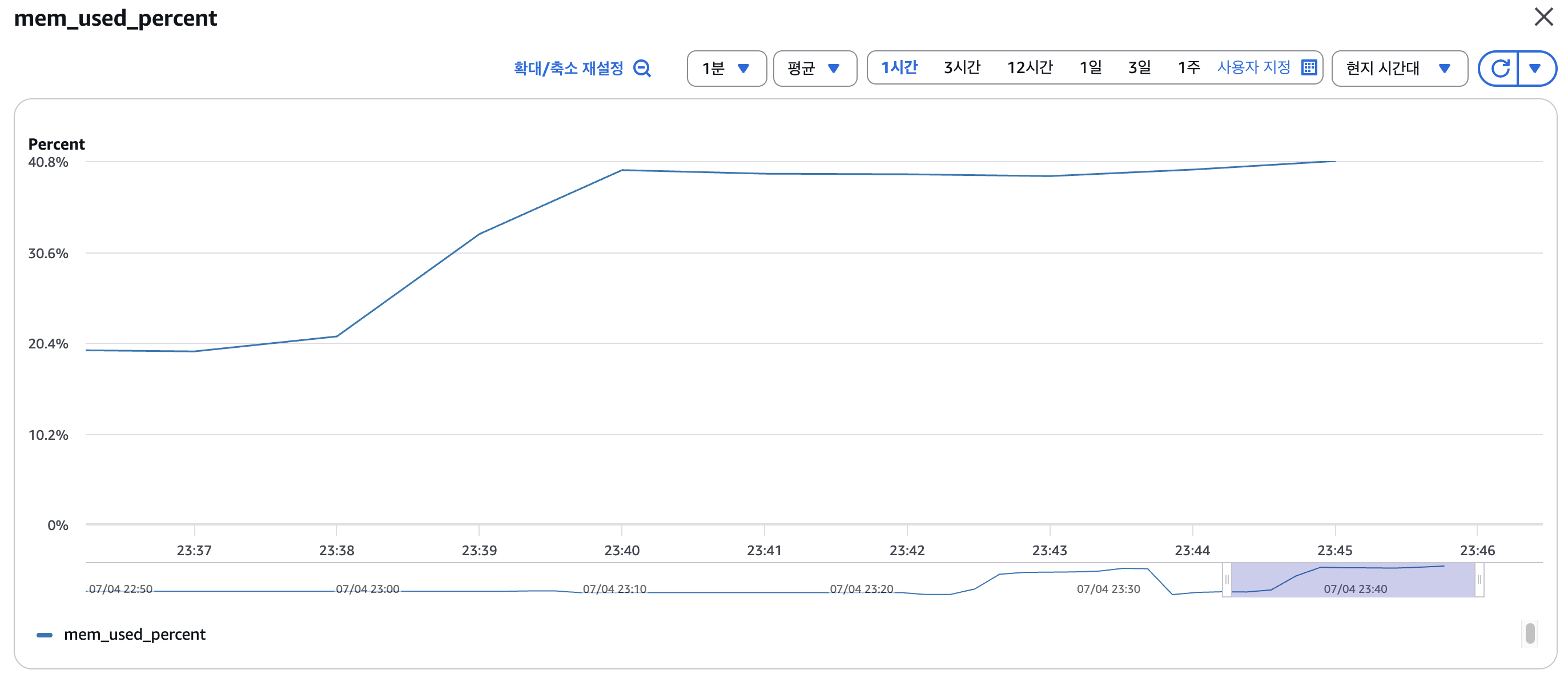
15,000명의 연결을 맺을 때 heap memory의 최대치에 근접한 것을 확인할 수 있었습니다. (기본 설정 2GB)
여유롭게 인스턴스 1대당 10,000개의 연결을 관리한다고 가정하겠습니다. 전체적인 os kernel의 메모리 사용량은 40%이기 때문에 jvm heap memory를 조절해 더 많은 연결을 관리하는것도 하나의 방법이겠지만, 현재 포스팅에서 중요한 부분은 아니라고 생각해 인스턴스 한 대당 10,000개의 연결을 관리한다고 가정하겠습니다.
즉 인스턴스 한 대당 10,000개의 연결이 적정값인데 100,000개를 연결해야 하는 상황이죠. 이 상황에서는 Scale-In, Scale-Out 두 가지 방법이 존재합니다.
각 방법은 장단점이 명확한데요, 여러 서버 관리가 힘들지어도 단일 SPOF를 예방하고자 Scale-Out 방법으로 구축을 해보겠습니다. 모니터링 환경을 잘 구축해놓으면 ASG를 통해서 서버 관리를 편하게 할 수 있다고 생각해요.
아키텍처는 다음과 같아집니다.
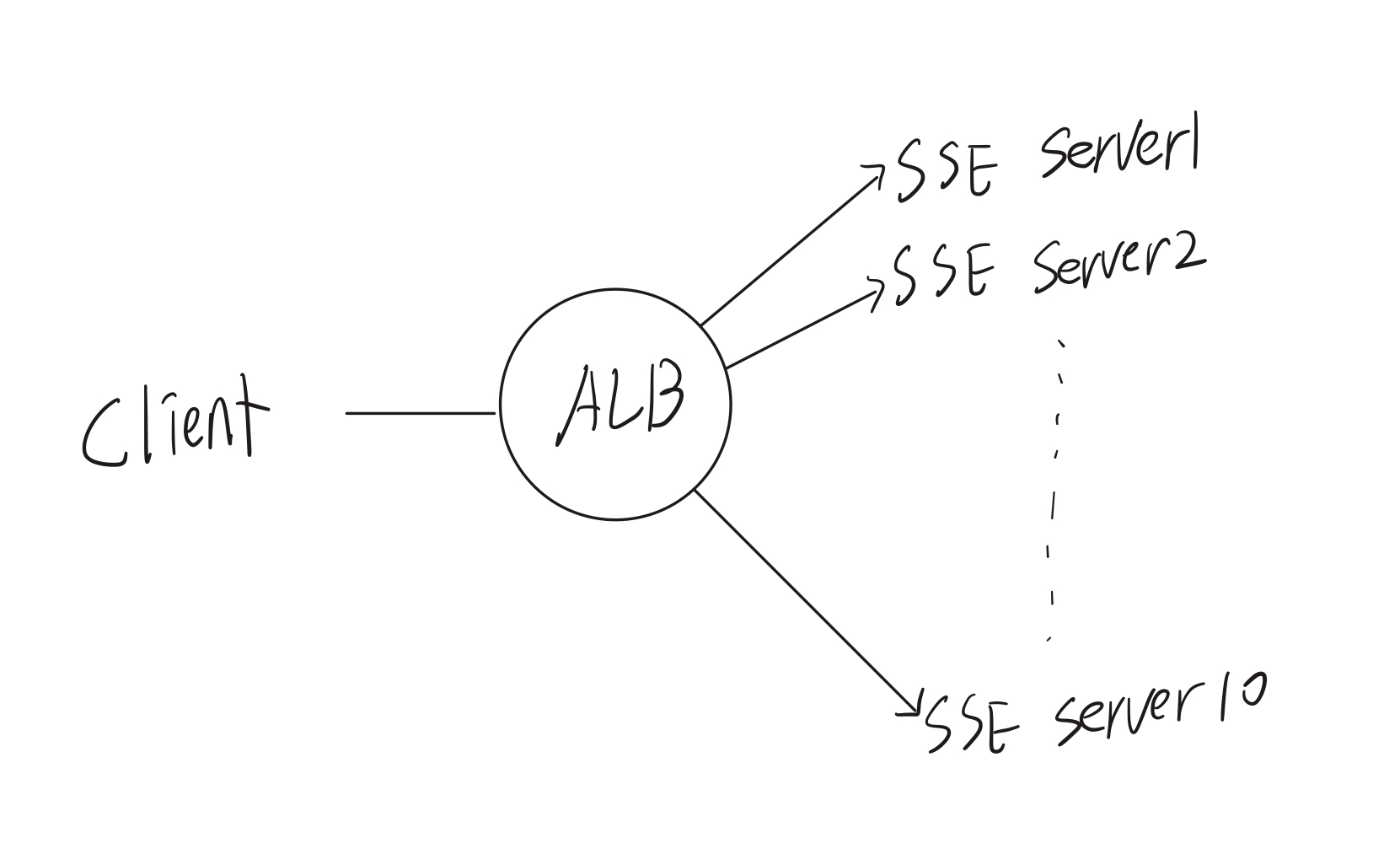
서버 당 10,000개의 SSE 연결을 관리할 수 있으니 10개의 SSE 서버가 필요하고, 앞단의 ALB에서 연결을 관리합니다.
그림을 보면 이런 생각을 할 수 있을 것 같은데요,
ALB가 터지면 서비스가 마비되는거 아니야?? ALB가 단일 SPOF처럼 보이는데...
Load Balancer는 언뜻 보기에는 하나의 물리적 기기처럼 보이지만, 내부적으로 여러 노드로 이루어져 있습니다. 구체적으로 몇 개의 노드를 사용하는지는 찾을 수 없었지만, 요청 수에 비례해 노드를 관리하겠죠?
개발자가 생각해야 하는 부분은 ALB의 LCU입니다. Node는 개발자가 관리할 수 없는 반면, LCU는 관리할 수 있습니다.
LCU란?
- Load Balancer Capacity Unit
1LCU당 관리할 수 있는 자원
- 초당 새 연결 25개
- 동시 활성 연결 3,000개
https://aws.amazon.com/ko/elasticloadbalancing/pricing/?utm_source=chatgpt.com
Elastic Load Balancing 요금
명시된 경우를 제외하고 요금에는 VAT 및 해당 판매세를 비롯한 관련 조세 공과가 포함되지 않습니다. 청구지 주소가 일본으로 되어 있는 고객의 경우 AWS 사용 시 일본 소비세의 적용을 받게 됩
aws.amazon.com
해당 지표는 모니터링 할 수도 있고 관리할 수도 있습니다. 트래픽이 갑자기 몰려올 때를 대비해 최소 LCU 사용량을 예약할 수도 있죠.
LCU 사용량이 많아진다 -> AWS 측에서 내부적으로 ELB Node 개수를 늘린다. 라고 이해할 수 있는것이죠.
해당 아키텍처에서 고려할 부분은 특정 SSE 서버가 터졌을 때 발생하는 재연결 문제입니다.
LCU가 너무 적게 활성화 되어 있다면 ALB Node가 Scale-out 하기 전에 요청이 쏠려서 RejectedConnectionCount 오류가 발생합니다. 이 상황을 대비해서 최소 LCU 사용량을 설정하는 것도 좋은 방법인 것 같네요. (단, 이 경우에는 연결이 없어도 최소 LCU가 활성화되어 있기 때문에 금액적으로 손해를 볼 수도 있을 것 같네요.)
TMI) 주의해야 할 부분
갑작스럽게 SSE 연결을 10,000개 관리해야 한다면 몇 개의 LCU를 예약해놔야할까요? 연결은 1초에 1,000개씩 몰린다고 가정해봅시다.
- 연결 유지 비용
1 LCU = 동시 활성 연결 3,000개
10,000 / 3,000 = 4 LCU
1 LCU = 초당 새 연결 25개
1,000 / 25 = 40 LCU
더 큰 값인 40 LCU 선택, 여유비용 20% 더해서 약 50 LCU 예약
이상적인 계산방법이지만, SSE에서는 추가로 고려해야 할 부분이 있습니다. 바로 ALB <-> Server 부분의 연결이 안 끊어진다는 것이죠.
기본적인 HTTP (Keep-alive 옵션이 켜져있을 경우)
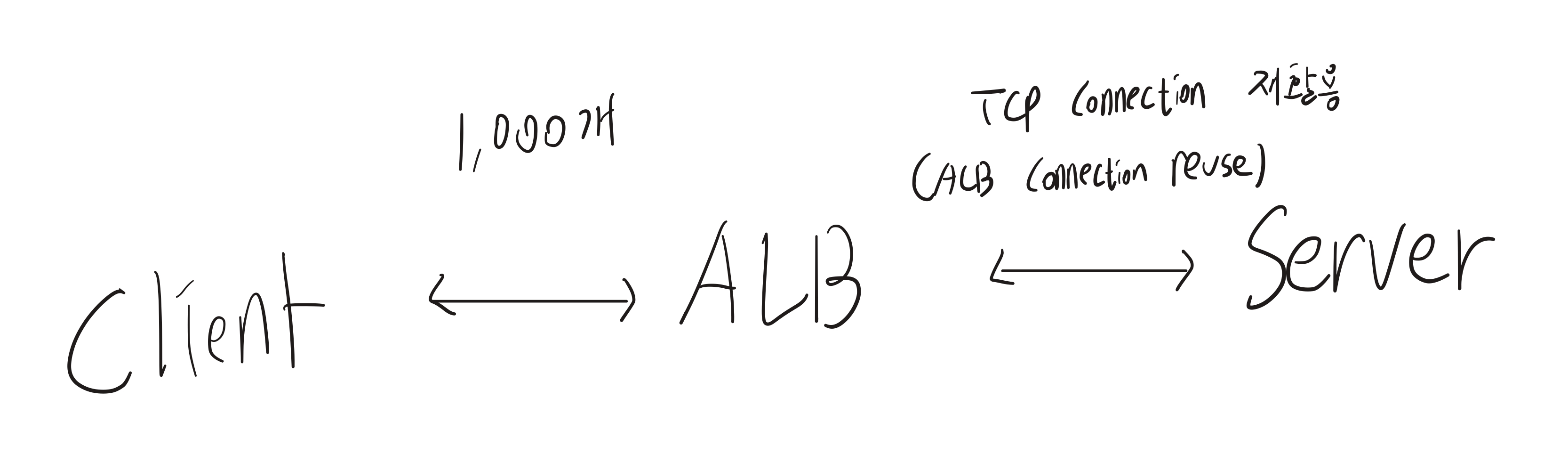
Server 측에서 Keep-alive 옵션이 켜져있을 경우 TCP Connection을 재활용합니다. 즉 이경우에는 ALB측에서 소수의 TCP Connetion의 정보만 가지고 1,000개의 ALB <-> Server TCP 연결을 관리할 수 있습니다.
SSE

SSE의 경우에는 TCP Connection을 재활용할수가 없습니다. 응답을 끝내지 않고 계속 물고있기 떄문에, 해당 TCP Connection은 다른 요청에 재활용 할 수가 없는 것이죠.
즉 SSE를 사용하는 경우에 Client 측으로부터 1,000개의 요청이 오면
Client <-> ALB (1,000개)
ALB <-> Server (1,000개)
총 2,000개의 TCP Connection을 ALB에서 관리를 해야하는 것이죠. 즉, LCU값을 다시 계산해보자면
1 LCU = 동시 활성 연결 3,000개
20,000 / 3,000 = 7 LCU
1 LCU = 초당 새 연결 25개
1,000 / 25 = 80 LCU
더 큰 값인 80 LCU 선택, 여유비용 20% 더해서 약 100 LCU 예약을 해야, ALB의 노드에 대해서 충분히 scale-out을 할 수 있는 것이죠.
(참고자료)

Using Load Balancer Capacity Unit Reservation to prepare for sharp increases in traffic | Amazon Web Services
Learn when and why LCU Reservation should be used and how to get started
aws.amazon.com
더 깊이 생각해보기)
LCU 예약을 하지 못 한 상태로 트래픽이 몰리거나, LCU 예약을 했지만 예상보다 트래픽이 더 많이 몰릴경우에는 RejectedConnectionCount를 직면할 수도 있습니다. Client측에서 재시도를 수행해도, 새로운 연결로 간주되기 때문에, 운이 나쁠 경우 계속해서 연결이 거부되거나 응답 지연이 발생할 수 있습니다.

시스템의 안정성을 강하게 확보하고 싶다면, ELB Sharding을 생각해볼 수 있을 것 같네요. 이 부분은 조금 더 학습이 필요할 것 같아, 공부 후 내용을 보충해놓을게요.
Scaling strategies for Elastic Load Balancing | Amazon Web Services
Elastic Load Balancing (ELB) offers four types of load balancers, all featuring high availability, automatic scaling, and robust security support for your applications: Application Load Balancer (ALB), Network Load Balancer (NLB), Gateway Load Balancer (GW
aws.amazon.com
이번 포스팅에서는 SSE Connection이 증가함에 따라 발생하는 문제에 대해 알아봤습니다. 다음 포스팅에서는 메시지 발송 시에 어떤 문제가 발생하는지 작성해볼게요!
'실험실' 카테고리의 다른 글
| 트랜잭션, 꼭 필요할까? (2) | 2026.02.08 |
|---|---|
| DB 통신 중 연결이 끊긴다면 어떻게 될까? (feat. JPA) (0) | 2025.06.14 |
| JWT payload를 조작하면 어떻게 될까? (feat. 어떻게 검증할까?) (2) | 2025.06.13 |


